(2) Fドライブの中に、Rのフォルダ(R-2.7.1)があります。そのフォルダの中にbin, libraryなどのフォルダがあります。
(3) R-2.7.1フォルダの中に、Rworkという名前の作業フォルダを新規作成します。
(4)Rworkの中に、データファイルdatahyou.datをおいてください。
| [2.1] データの読み込み |
| [2.2] データフレーム |
| [2.3] ヒストグラム描画 |
| [2.4] 折れ線グラフ描画 |
| [2.5] グラフの重ね書き |
(1) USB フラッシュメモリは、F:ドライブが割り当てられているものと仮定します。
(2) Fドライブの中に、Rのフォルダ(R-2.7.1)があります。そのフォルダの中にbin, libraryなどのフォルダがあります。
(3) R-2.7.1フォルダの中に、Rworkという名前の作業フォルダを新規作成します。
(4)Rworkの中に、データファイルdatahyou.datをおいてください。
Rを起動するには、F:\R-2.7.1\bin\Rgui.exeをダブルクリックします。次のような、初期画面が立ち現れます。
赤色に表示されている">"(プロンプト記号)から始まる行(コマンドライン)に、Rに対する作業命令をタイプ入力し、最後にリターンキーを押して、命令を伝えます。
Rを終了するには、コマンドラインに q() と入力するか、スクリーン右上の×印をクリックしてください。作業内容を保存するかどうかに答えると終了します。
よく使うコマンドには次のようなものがあります。
| R の関数を使いこなそう | |
| ls() | Rに保存されているデータ(オブジェクト)の一覧を表示する |
| rm(x) | 保存されているデータ(オブジェクト)xを削除する |
| getwd() | 作業ディレクトリ(フォルダ)を表示する |
| setwd(xxx) | 作業ディレクトリ(フォルダ)をxxxに設定する xxxはフォルダのパス |
| q() | Rでの作業を終了する。 |
この授業では、asahi98.datという名のテキストファイルに書かれているデータセットを分析していきます。このファイルには、2,472件の投書に関して、ケース番号、性別、年齢の他に、漢字使用率など15の文体項目に関して分析した結果が、タブで区切られて記載されています。第1行目は、(英語表記された)項目の見出し行(header)です。
このデータファイルのパスは、"F:\\Rwork\\asahi98.dat"とします。asahi98.datのような、タブで区切られたデータファイルを読み込むには、read.table( )関数を使います。この関数のかっこの中に、データファイルのパスを指定します。
また、asahi98.datの先頭行は見出し行となっていますので、読み込みの際のオプションとしてheader=TRUEを指定します。オプションは、オプション名=値という形で指定します。
read.table( )は、指定されたファイルの読み込み、その内容をそのままRの画面に書き出して終了します。このデータを使っていろいろと作業をしたいときには、読み込んだデータをオブジェクト名をつけて保存しておきます。変数 <- 値は、右辺の値を左辺の変数に代入(格納、保存)する働きをします。
オブジェクト変数は自由に決められます。ただし、数字から始まる変数名は使えません。また、大文字と小文字が区別されますので、変数xと変数Xは別物と扱われます。変数名は、入力し易いように半角英数を用いるとよいでしょう。ここでは、asahi98.datのデータ内容を、asahi.dfという変数に格納することにします。
オブジェクト変数の名前(たとえば、asahi.df)をコマンド入力すると、そこに格納されている値がRの画面に表示されます。膨大な量のデータが急速に画面表示されても人間の側がついていけません。基本的な構造をチェックするには、データの最初の部分が表示されれば十分でしょう。head( )関数を使うと、指定されたデータの最初の6行が画面表示されます。
asahi.df <- read.table( "F:\\Rwork\\asahi98.df", header=TRUE )
head( asahi.df ) # 最初の6行を表示
No sex age kanji noun MVR VNR demon past simili color
1 1 <NA> 16 25.53 58.97 5.41 53.62 2.56 33.33 0 0
2 2 M 14 22.55 51.61 32.00 52.08 6.45 72.73 1 0
3 3 F 15 23.39 53.24 16.67 56.76 3.60 53.85 0 1
4 4 M 18 32.30 55.77 13.33 51.72 1.92 0.00 0 0
5 5 F 15 29.28 56.73 12.12 55.93 3.85 28.57 0 0
6 6 M 18 36.74 65.00 11.11 39.56 0.71 25.00 0 0
onom idiom yoji slength quote kata basic
1 2 0 0 26.25 6.67 4 26.74
2 0 1 0 27.92 5.67 2 24.36
3 0 1 0 35.14 0.81 4 29.31
4 0 0 0 38.30 8.09 2 34.67
5 0 1 0 45.13 4.99 8 28.57
6 0 1 0 52.89 3.15 6 37.35| R の関数を使いこなそう | |
| read.table( "ファイルパス" ) | データファイルを読み込む |
| header=TRUE | 先頭行が見出し行のとき、TRUE |
| head( 変数名 ) | 先頭の6データを表示する n行分を表示するときは、head(変数名, n)とする |
| 変数 <- 値 | 右辺の内容(値)を左辺の変数に代入(格納)する |
asahi.dfというオブジェクトは、見出し行と2,472行のデータ行から成り、各行には18項目(列)に関する値が含まれています。つまり、 asahi.dfは、行と列からなる表形式のデータです。read.table( )で読み込んだデータはデータフレーム型のオブジェクトとして保存されます。
print( )関数のカッコの中にオブジェクトの名前を渡すと、そのオブジェクト名で保存されている内容が画面に表示されます。print( ) の部分は省略できますので、オブジェクト名を打つだけでもその内容が表示されます。
データフレーム中の第m行第n列にアクセスするには、データフレーム名[m, n]とします。行番号と列番号はカンマで区切ります。行や列の番号を指定しないと、行や列の全部を指定したと同じことです。
asahi.df[1, 4] # 第1行第4列にあるデータを表示
[1] 25.53
asahi.df[2, ] # 2行目のデータをすべて表示
No sex age kanji noun MVR VNR demon past simili color onom
2 2 M 14 22.55 51.61 32 52.08 6.45 72.73 1 0 0
idiom yoji slength quote kata basic
2 1 0 27.92 5.67 2 24.36
asahi.df[, 3] # 3列目のデータをすべて表示
[1] 16 14 15 18 15 18 18 19 18 18 17 18 17 15 15 17 18 19 18 14
[21] 17 18 17 18 16 12 13 15 19 18 17 12 14 16 15 18 14 17 18 16
[41] 15 18 19 10 18 17 16 16 16 19 17 18 17 14 16 15 18 17 17 12
[61] 18 13 14 15 19 17 17 17 15 18 18 18 18 17 14 17 15 14 15 15
[81] 15 14 14 19 15 14 16 15 17 10 14 19 17 19 19 19 15 18 16 16
[101] 14 15 17 14 18 16 16 12 18 12 17 11 19 17 12 22 24 28 29 25
... (以下省略)データフレーム中の、連続している行や列にアクセスするには、":"という記号を使い、始まりの番号と終わりの番号を指定します。下の例を見ると、わかりやすいでしょう。
asahi.df[1:3, ] # 1〜3行目データ
No sex age kanji noun MVR VNR demon past simili color onom idiom
1 1 16 25.53 58.97 5.41 53.62 2.56 33.33 0 0 2 0
2 2 M 14 22.55 51.61 32.00 52.08 6.45 72.73 1 0 0 1
3 3 F 15 23.39 53.24 16.67 56.76 3.60 53.85 0 1 0 1
yoji slength quote kata basic
1 0 26.25 6.67 4 26.74
2 0 27.92 5.67 2 24.36
3 0 35.14 0.81 4 29.31
asahi.df[1:3, 2:4] # 1〜3行目の2〜4列目データ
sex age kanji
1 16 25.53
2 M 14 22.55
3 F 15 23.39
| R の関数を使いこなそう | |
| print( オブジェクト名 ) | オブジェクトの内容を表示する |
| データフレーム名[行番号, 列番号] | 指定された行、列にあるデータを表示 |
| データフレーム名[行番号, ] | 指定された行のすべての列データを表示 |
| データフレーム名[, 列番号] | すべての行の指定された列のデータを表示 |
| データフレーム名 | すべての行のすべての列のデータを表示 |
asahi.dfには先頭に見出し行がついています。データフレーム名の後に"$"記号をつけて、この見出し(=列変数名)をつけると、指定した列データにアクセスすることができます。
ただし、特定のデータセット、たとえばasahi.dfを対象に本格的に作業をしようとすると、データフレーム名$列変数名を何度も入力しなければなりません。でも入力の手間がかなり面倒です。そのような時は、attach( )関数を使って、データセットを登録します。一度登録すると、列変数名を入力するだけで同じ結果が得られます。
データセットを登録しておく必要がなくなったとき、あるいは、別のデータフレームを登録する前に、detach( )関数を使って、データセットを登録解除を行います。 (注)Rを終了することにより、データセットは自動的に登録解除されます。
head( asahi.df$kanji ) # kanji列の先頭6データ
[1] 25.53 22.55 23.39 32.30 29.28 36.74
attach( asahi.df ) # データセットを登録
head( kanji ) # 変数名だけ
[1] 25.53 22.55 23.39 32.30 29.28 36.74
| R の関数を使いこなそう | |
| attach( データフレーム名 ) | データセットを登録 |
| detach( データフレーム名 ) | データセットの登録を解除 |
| データフレーム名$列変数名 | 指定した列変数データを表示 データセットを登録していないとき |
| 列変数名 | 指定した列変数データを表示 データセットを登録してあるとき |
asahi.dfの第3列は投稿者の年齢を表すデータです。年齢データを連続変数とみなして、ヒストグラムを描画してみましょう。
年齢データは、第1行のデータから最終行のデータまで、2472個のデータが並んでいるデータです。このように一連の値が並んで1まとまりになっているものをベクトルといいます。asahi.df$ageデータはベクトルデータの一種です。
Rでヒストグラムを描画するには、hist( )を使って、数値ベクトルの変数名を指定します。その際、クラスの区間を通常は「〜以上〜未満」として集計しますので、right=FALSEというオプションを忘れずに指定してください。hist( )のように、ある決まった作業を行う命令を関数とかメソッド(method)といいます。メソッドの中には、作業を行うために決まった種類の値を受け取る 必要のあるものがあります。メソッドに渡される値のことを引数(ひきすう)と言います。引数はメソッドの括弧の中に書きます。
# 年齢データのヒストグラムを描画
hist( age, right=FALSE )

|
実行すると、あっけないほど簡単にヒストグラムが描画されます。
デフォルトの場合、メインタイトルは"Histgram of ベクトル変数名"となり、X軸ラベルはベクトル変数名、Y軸ラベルは"Frequency"と表示されます。
もしデフォルトではない形式を表示させたい場合は、hist(
)に対して、オプション指定を行います。オプション指定は、オプション変数の後に等号"="をつけ、数値や文字列あるいはTRUE/FALSEの論理値を指定します。文字列の場合はその前後をダブルクォートで囲みます。
(注1)right=FALSEもオプション指定です。rightとは各級間の上限値を含める(TRUE)か、含めない(FALSE)かの指定です。通常、上限値はx未満ですので、right=FALSEを指定する必要があります。
(注2)クラス数、クラス間隔、Y軸目盛りなどもオプションで指定できますが、Rが最適な形式を自動計算して表示しますので、通常は変更の必要がないでしょう。
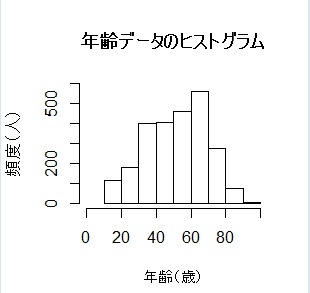
デフォルトでは年齢を5歳刻みでクラス分けしていましたが、ここでは10歳刻みにして、ヒストグラムを作成してみます。その他、X軸・Y軸の表示範囲を広げ、タイトルや軸ラベル名を日本語表記にしてみます。
# 年齢データのヒストグラムを描画
hist( age, right=FALSE,
breaks=c( 10, 20, 30, 40, 50, 60, 70, 80, 90, 100 ),
xlim=c( 0, 100 ),
ylim=c( 0, 600 ),
xlab="年齢(歳)",
ylab="頻度(人)",
main="年齢データのヒストグラム" )
|
| R の関数を使いこなそう | |
| hist( 列変数名 ) | 対象データのヒストグラムを描画する |
| right=FALSE | 級間上限値を含まない 「〜以上〜未満」とする |
| breaks=数値ベクトル | 級の境界となる数値 |
| xlim=c(始点, 終点) | X軸の目盛範囲 |
| ylim=c(始点, 終点) | Y軸の目盛範囲 |
| main="タイトル文字列" | グラフタイトル(キャプション)を表示する |
| xlab="文字列" | X軸ラベル |
| ylab="文字列" | Y軸ラベル |
作成したグラフをファイル形式で保存する前に、グラフィックス画面のサイズを調整して、グラフの見栄えを良くします。特に、グラフの縦横の比、グラフの描画サイズと比較してタイトルや軸の文字が大き過ぎたり、小さ過ぎないように調整します。グラフ全体のサイズは後で自由に調整可能です。
|
グラフィックス画面のメニューから[ファイル]→[別名で保存]を選択すると、保存可能な画像ファイル形式が表示されます。たとえば、[Jpeg] を選択すると、さらに[100%の品質...]などを指定することができます。あとは、ファイル名と保存場所を指定して[OK]を押します。一度保存した 画像ファイルは、他の画像ファイルと全く同様に、文書ファイルやプレゼンファイルに貼り付けることができます。
次に、年齢データの累積相対度数を折れ線グラフで描画してみましょう。
そのための手順は次のようになります。
(1) 10歳刻みの年齢クラスを作り、各クラスに属する人数(度数)を求める。
(2) 各クラスの相対度数を計算する。
(3) 各クラスの累積相対度数を計算する。
(4) 累積相対度数のデータを折れ線グラフで描画する。
10歳から100歳まで10歳刻みで年齢クラスを作り、各クラスに属するデータ数を集計します。
まず、クラスとクラスの境界値を格納するベクトルを作成します。ベクトルデータを作成するにはc( )やseq( )を使う方法があります。c( )には、データをカンマで区切って順に列挙します。seq( )関数は、始点、終点、および刻み幅を指定します。今のケースのように、要素にパタンがあるときはseq( )を使うのが便利です。
c( 10, 20, 30, 40, 50, 60, 70, 80, 90, 100 )
[1] 10 20 30 40 50 60 70 80 90 100
seq( 10, 100, 10 )
[1] 10 20 30 40 50 60 70 80 90 100
次に、cut( )関数を使って、各データをどれかのクラスに振り分け、その結果を変数に格納します。その結果データをtable( )関数に渡して、各クラスの度数を集計します。
age.class <- cut( age, breaks=seq( 10, 100, 10 ), right=FALSE,
ordered_result=TRUE )
head( age.class ) # 年齢クラス分けされた先頭6データ
[1] [10,20) [10,20) [10,20) [10,20) [10,20) [10,20) # いずれも「10以上20未満」のクラス
9 Levels: [10,20) < [20,30) < [30,40) < [40,50) < [50,60) < ... < [90,100)
( age.tab <- table( age.class ) )
age.class
[10,20) [20,30) [30,40) [40,50) [50,60) [60,70) [70,80) [80,90) [90,100)
115 179 400 407 459 560 274 73 5
次に、各クラスの相対度数、すなわち、各クラスの度数の、全体に対する割合(パーセント)を計算します。合計(総和)を求めるには、sum( )関数に対象データを渡します。総計をtotalという変数に格納しておきます。
3行目にある"age.tab/total*100"という部分で、各クラスの相対度数を求めています。age.tabという変数は9個のデータから成り立っていますので、それぞれの値を総数totalで割り、100を乗じる計算が順に行われ、9個の相対度数が計算される訳です。その結果をpctという変数に格納しておきます。
最後に、累積相対度数を計算します。1番目から9番目まで順に i 番目の相対度数を加算していき、その累積の値が i 番目のクラスの累積相対度数となります。このような同じ計算処理の繰り返しは、for ループを使います。累和を計算の際には、左辺と右辺に同じ変数が出てきますが、先に左辺の値を計算して、それが"<-"の働きで左辺に代入されることに注意してください。
# 相対度数rel を計算する
( total <- sum( age.tab ) )
[1] 2472
( rel <- age.tab / total * 100 )
age.class
[10,20) [20,30) [30,40) [40,50) [50,60) [60,70)
4.6521036 7.2411003 16.1812298 16.4644013 18.5679612 22.6537217
[70,80) [80,90) [90,100)
11.0841424 2.9530744 0.2022654
# 累積相対度数cumを計算する
rel.sum <- 0 # 相対度数合計 rel.sum の値を初期化
n <- length( rel ) # データの数
cum <- numeric( length=n ) # 9個の累積相対度数を入れるベクトル変数
for ( i in 1:n ) { # relの個数分、処理を繰り返す
rel.sum <- rel.sum + rel[i] # 相対度数を累加
cum[i] <- rel.sum # 累積の値を格納
}
cum # 結果を表示
[1] 4.652104 11.893204 28.074434 44.538835 63.106796 85.760518
[7] 96.844660 99.797735 100.000000以上で、度数頻度表の作成に必要なデータが揃いました。相対頻度と累積相対頻度のデータを、年齢クラスの頻度表の列として追加します。これには列(column)結合(bind)のcbind( )を使います。ちなみに、行(row)として追加するにはrbind( )関数を使います。cbind( )やrbind( )の結果作られる表データは行列(matrix)オブジェクトとなります。
結果を見ると、relとcumの値は桁数が多すぎるようですので、round( )関数を使って、小数点第3位で四捨五入して、第2桁まで表示することにしましょう。
cbind( age.tab, rel, cum )
age.tab rel cum
[10,20) 115 4.6521036 4.652104
[20,30) 179 7.2411003 11.893204
[30,40) 400 16.1812298 28.074434
[40,50) 407 16.4644013 44.538835
[50,60) 459 18.5679612 63.106796
[60,70) 560 22.6537217 85.760518
[70,80) 274 11.0841424 96.844660
[80,90) 73 2.9530744 99.797735
[90,100) 5 0.2022654 100.000000
class( age.freq.table )
[1] "matrix"
age.freq.table <- cbind( age.tab, round( rel, 2 ), round( cum, 2 ) )
age.tab
[10,20) 115 4.65 4.65
[20,30) 179 7.24 11.89
[30,40) 400 16.18 28.07
[40,50) 407 16.46 44.54
[50,60) 459 18.57 63.11
[60,70) 560 22.65 85.76
[70,80) 274 11.08 96.84
[80,90) 73 2.95 99.80
[90,100) 5 0.20 100.00年齢データの度数分布表age.freq.tableの行見出しと列見出しを整えます。表データの行変数名と列変数名として、文字列ベクトルを代入します。これで度数分布表が完成しました。
rownames( age.freq.table )
[1] "[10,20)" "[20,30)" "[30,40)" "[40,50)" "[50,60)" "[60,70)"
[7] "[70,80)" "[80,90)" "[90,100)"
colnames( age.freq.table ) <- c( "freq", "rel.freq", "cumul.freq" )
age.freq.table
age.freq.table
freq rel.freq cumul.freq
[10,20) 115 4.65 4.65
[20,30) 179 7.24 11.89
[30,40) 400 16.18 28.07
[40,50) 407 16.46 44.54
[50,60) 459 18.57 63.11
[60,70) 560 22.65 85.76
[70,80) 274 11.08 96.84
[80,90) 73 2.95 99.80
[90,100) 5 0.20 100.00
| R の関数を使いこなそう | |
| c( a, b, c, ... ) | ベクトルの要素を順に列挙する 結合するデータには、数値、文字列、論理値をはじめ、各種オブジェクトも可 |
| seq( 始点、終点、刻み幅 ) | 始点から終点まで等差で分割したベクトルを作る |
| rep( パタン, 繰り返し回数 ) | パタンを指定回数分繰り返したベクトルを作る パタンには数値、文字列の他、c( )で結合したベクトルも可 |
| cut( ベクトル変数名, 境界値ベクトル ) | 境界値ベクトルを使って、対象データを分割する |
| right=T/F | クラスに上限値を含めないときはright=FALSEを指定する |
| labels=c( ... ) | 各クラスの名前を表す文字列ベクトル |
| table( ベクトル変数名 ) | 対象データを要因(factor)ごとに集計する |
| sum( ベクトル変数名 ) | データの合計を算出する 表データを渡すと、総計を算出する |
| round( データ, 小数点以下表示桁数 ) | データを指定された桁に丸める |
| rbind( 表形式データ, 行データ名 ) | 表形式データの最後に行データを追加する |
| bind( 表形式データ, 列データ名 )c | 表形式データの最後に列データを追加する |
年齢データの累積相対頻度を折れ線グラフで描画します。折れ線グラフを描くには、matplot( ) という関数もありますが、ここではより一般的なplot( )を使うことにします。plot( )は、X座標とY座標を指定して点をプロットすることにより散布図などを描きます。したがって、plot( )はXとY座標の数値ベクトルの指定を必要とします。そして、点と点を順に結ぶ線を付ければ、折れ線グラフが出来上がります。これはオプションでtype="b"を指定します。
plot( )には多くのオプション指定が可能ですが、後々、折れ線グラフとヒストグラムを重ね描きすることを念頭において、X軸の範囲をヒストグラムと共通にすること、Y軸目盛をデフォルトの左側ではなく、右側に付けるようにします。そのためには、オプションで"axes=F"によりすべての軸目盛をつけないように指定してから、axis( )を使って、必要な個所に目盛を追加します。
# 累積相対度数を折れ線グラフに描画する
( xvals <- seq( 15, 95, 10 ) )
[1] 15 25 35 45 55 65 75 85 95
( yvals <- cum )
[1] 4.652104 11.893204 28.074434 44.538835 63.106796 85.760518
[7] 96.844660 99.797735 100.000000
plot( xvals, yvals, # データを
type="b", pch=1, # ○点と線で
xlim=c(0, 100), ylim=c(0,100), # X軸、Y軸の範囲
xlab="", ylab="", # 軸ラベルなし
axes=F ) # 軸目盛を自動で描画しない
axis(1, at=xvals, labels=rownames(age.freq.table) ) # X軸目盛を表示
axis(4) # 第2Y軸目盛を表示
box() # グラフ部分を枠線で囲む
title( "年齢データの累積相対頻度" ) # グラフタイトルを追加

|
| R の関数を使いこなそう | |
| plot( x座標ベクトル, y座標ベクトル, | x,yは数値ベクトル |
| type=データの表示方法 | "p":点、"l":線、"b":点と線の両方、"n":表示しない |
| lty=線のタイプ | 1:実線、2:破線、3:実線と点 |
| lwd=数値 | 線の太さ、1が基準で、大きいほど太くなる |
| col=色名 | 1:"black", 2:"red", 3:"blue"など |
| xlim=c(始点、終点) | X軸の目盛範囲 |
| ylim=c(始点、終点) | Y軸の目盛範囲 |
| xlab="文字列" | X軸のラベル名(表示させないときはxlab="") |
| ylab="文字列" | X軸のラベル名(表示させないときはylab="") |
| main="文字列" | グラフのタイトル(キャプション) |
| axes=FALSE | 軸の目盛を表示しない |
| text( x, y, "文字列" ) | 図中の座標(x, y)を中心に、文字列を追加する |
| title( "文字列" ) | グラフのタイトル(キャプション)を追加する |
| axis( 軸の位置, labels=c(目盛文字列) ) | 1:下、2:左、3:上、4:右(グラフから見て) |
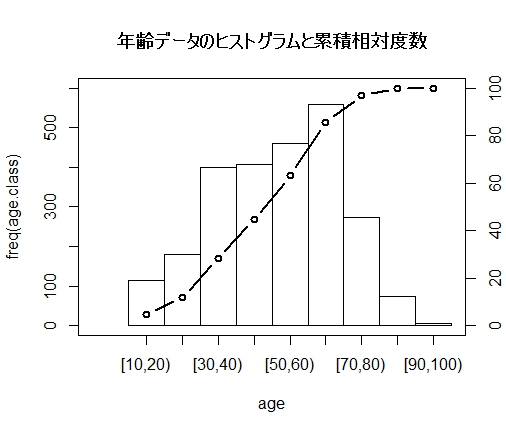
年齢データに関して、度数分布を棒グラフで、累積相対度数を折れ線グラフで描画しました。ここでは、これら2つのグラフを重ね描きすることにします。
グラフの重ね描きのポイントは、次の3点です。
# 棒グラフと折れ線グラフを重ね描きする
hist( age, right=FALSE, breaks=seq(10, 100, 10 ), # ヒストグラム
xlim=c( 0, 100 ), ylim=c( 0, 600 ), # X, Y軸目盛範囲
xlab="age", ylab="freq(age.class)",
axes=FALSE )
axis( 2 ) # グラフ左側に第1Y軸を表示
par( new = T ) # 重ね描き宣言
plot( seq( 15, 95, 10 ), cum, # 折れ線グラフ
type="b", pch=1, lwd=2,
xlim=c( 0, 100 ), ylim=c( 0, 100 ),
xlab="", ylab="", axes = FALSE )
axis( 1, at=seq( 15, 95, 10 ), labels=rownames( age.freq.table ) )
axis( 4 ) # グラフ右側に第2Y軸を表示
box()
title( "年齢データのヒストグラムと累積相対度数" )
|
| R の関数を使いこなそう | |
| par( new=T ) | グラフの重ね描きを宣言 |
ある数量データをクラス区間で分けて、度数分布表とともにヒストグラムと折れ線グラフ描画を行う自作関数を定義しておけば、便利かもしれません。下のRスクリプトをfreqtable.Rというファイルで保存しておき、対象データ名、クラス分け始点、終点、クラス幅を引数として指定して使います。
# ----------- [ freqtable.R ] ---------
# 対象の数量データの度数頻度表と、ヒストグラムと累積頻度をグラフ表示する
# usage: freqtable( target.vector, from, to, by )
# arguments: target.vector=対象となる数量ベクトル変数名
# from=始点, to=終点, by=クラス幅
# by Kaoru Fukuda, on Dec. 11, 2012
freqtable <- function( target.vector, from, to, by ) {
# 度数分布表の作成
res <- cut( target.vector, breaks=seq( from, to, by ), right=FALSE,
ordered_result=TRUE )
res.tab <- table( res )
total <- sum( res.tab )
relfreq <- res.tab / total * 100
rel.sum <- 0
n <- length( relfreq )
cumfreq <- numeric( length = n )
for ( i in 1:n ) {
rel.sum <- rel.sum + relfreq[i]
cumfreq[i] <- rel.sum
}
freq.tab <- cbind( res.tab, round( relfreq, 2 ), round( cumfreq, 2 ) )
colnames( freq.tab ) <- c( "freq", "rel.freq", "cumul.freq" )
print( freq.tab )
# ヒストグラムと累積相対度数を描画する
hist.data <- hist( target.vector, right=FALSE, breaks=seq( from, to, by ),
xlim=c( from, to ), xlab="", ylab="", main="", axes=F )
axis( 2 )
par( new = T )
mids <- hist.data$mids # ヒストグラムの棒の中点X座標
plot( mids, cumfreq, type="b", xlim=c( from, to ), ylim=c( 0, 100 ),
xlab="", ylab="", pch=1, lwd=2, axes=F )
axis( 1, at=mids, labels=rownames( freq.tab ) )
axis( 4 )
box()
}
下は、漢字率データをfreqtable( )で描画するコマンドです。
summary( 対象ベクトル名 )関数で、最小値、最大値などの基本統計量を知ったうえで、freqtable( )に対して、適切な引数の値を指定します。
# 漢字率データの度数分布グラフを描画する
summary( kanji )
Min. 1st Qu. Median Mean 3rd Qu. Max.
13.93 27.85 31.84 32.22 36.20 54.05
freqtable( kanji, 10, 60, 5 )
title( "漢字率データのヒストグラムと累積相対頻度" )

|