| [3.1] 基本統計量 |
| [3.2] グラフの作成 |
| [3.3] カテゴリデータの散らばり指数 |
Rには統計量を計算するための関数が豊富に組み込まれています。これらの関数に対してデータ名(ベクトル変数名)を引数として与えると、統計量を計算して表示してくれます。
| R の関数を使いこなそう | |
| length( データ変数名 ) | データ数 |
| mean( データ変数名 ) | 平均値 |
| median( データ変数名 ) | メディアン(中央値) |
| var( データ変数名 ) | 分散 |
| sd( データ変数名 ) | 標準偏差 |
| quantile( データ変数名 ) | パーセンタイル点(0%, 25%, 50%, 75%, 100%) |
| summary( データ変数名 ) | 最小値、Q1、中央値、平均、Q3、最大値 |
Rは、各種グラフを描画する関数も豊富に用意されています。ここでは、箱ひげ図、棒グラフ、帯グラフを描いてみます。
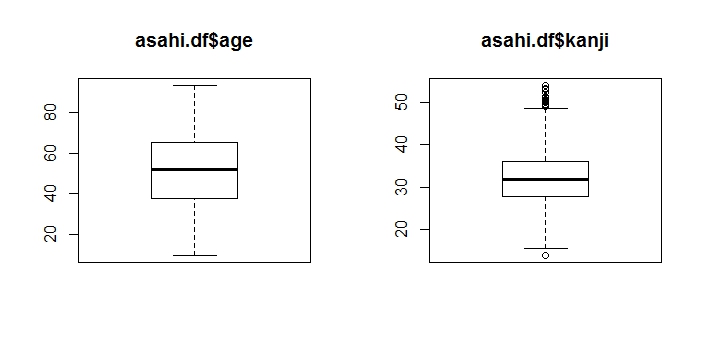
箱ひげ図はboxplot( )関数に数量データを指定するだけで描画できます。
箱ひげ図の箱の中の太い線は中央値、箱の底辺は25%点(Q1)、箱の上辺は75%点(Q3)の値です。箱の長さは、75%点と25%点の差、すなわち四分位範囲の値を表します。
通常、箱の上下から延びる「ひげ」の長さは、箱の長さの1.5倍に設定されています。たとえば、下のひげは(25%点-1.5*四分位範囲)の値に引かれます。最小値、最大値が1.5倍範囲内に収まるときには、それらの値が上下のひげの端となります。上下のひげの範囲から外にはずれる値を「はずれ値」(異常値)といい、それらは点で示されます。
|
|
Rでは、データを層(グループ)ごとに分け、各層のグラフを描画することも簡単にできます。基本は、対象データ~層を表すデータという形式を引数に渡します。

|
| R の関数を使いこなそう | |
| hist( 数量データ変数名 ) | ヒストグラムを描画 |
| right=T/F | クラス区間の上限値をクラスに含めるかどうか 「〜以上〜未満」とするときはright=FALSE |
| boxplot( データ変数名 ) | 箱ひげ図 |
| boxplot( データ変数名~要因変数名 ) | 箱ひげ図(グループごと) |
| main="タイトル" | タイトル文字列を表示 |
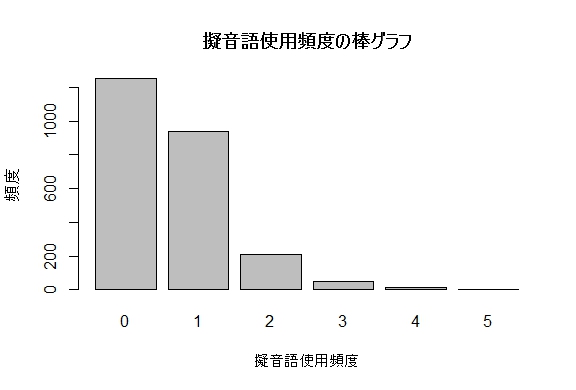
カテゴリデータの要因ごとの頻度は棒グラフで表示します。xtabs( ~ 変数名 )で作成した頻度表をbarplot( )に渡して作ります。たとえば、投書中の擬音語数onomは 0〜5 の整数値を取ります。これらはxtabs( )の引数としては要因として型変換されます。
|
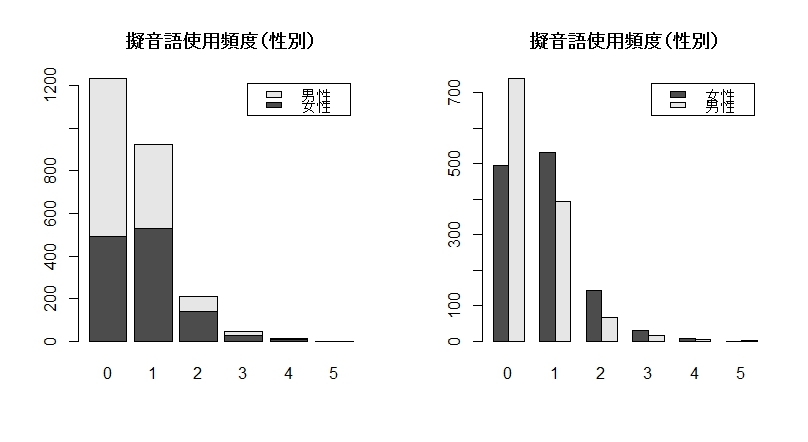
カテゴリデータ同士の分割表は、xtabs( ~変数1+変数2)で作ります。頻度表においては、変数2の方が列変数となり、棒グラフではX軸に表示されます。
次の例は、性別と擬音語使用回数で頻度表を作り、それを棒グラフで表します。
(注)asahi.datには全部で2,472件のデータがありますが、性別データには42件の欠損値("<NA>")が含まれていますので、頻度集計の合計は2,430件になります。これらの欠損値は、xtabs( )で頻度集計する時、自動的に除外されます。
|
円グラフや帯グラフは、全体に対する各部分の割合を表示します。帯グラフを作成するには、頻度集計した結果をprop.table( )関数で割合の表に変換します。割合の頻度表をbarplot( )に渡します。horiz=TRUEを指定すると、棒が横に描かれます。
例として、擬音語使用回数カテゴリの性別割合を帯グラフに描画します。擬音語使用回数は0回から5回まで5カテゴリがありますが、2回以上は頻度が少ないので1つにまとめることにします。

|
barplot( )は、戻り値として、それぞれの棒の中点の位置を返します。これらの値を利用すると、たとえば、棒の上に頻度データを表示したり、95%信頼区間などを追加することができます。rectangular_graph( )は、2つのカテゴリ変数の頻度表から帯グラフを描画し、さらに、割合の値を帯グラフの各セルの中央の位置に書き込むための、自作関数です。

|
| R の関数を使いこなそう | |
| xtabs( ~ データ変数名 ) | カテゴリデータの頻度集計 |
| xtabs( ~ 変数名1 + 変数名2 ) | 2変数による頻度分割表 |
| barplot( 表または行列データ ) | カテゴリデータの棒グラフ |
| beside=TRUE | 棒を横に並べる(省略すると積み重ね) |
| space=0 | 棒の間隔を0にする(ヒストグラム) |
| horiz=TRUE | 棒を水平にする |
| col="色名" | 棒の色を指定 |
| legend=c("変数名", ...) | 凡例に表示する文字列 |
| plot( 変数1, 変数2 ) | 変数1(X軸)と変数2(Y軸)の散布図 (注)データ数が同じであること |
| plot( x座標ベクトル, y座標ベクトル ) | 散布図 |
| type="b" | 折れ線グラフ(点と線の両方) |
カテゴリデータの散布度の指標の一つ、散らばり指数Dの値を求めましょう。ここでは、4字熟語使用回数のデータを男女別に分けて頻度データを作り、それぞれの散らばり指数を計算し、どちらのデータがより散らばっているかを比較してみましょう。手順は、次のようになります。
(1) (カテゴリデータの頻度表を作り)、頻度データをベクトルに格納する。
(2) 頻度ベクトルを受け取って散らばり指数の値を返す関数を作る。
(3) この関数を使って、散らばり指数を計算する。
xtabs( )を使うと、柔軟な分割表集計ができます。引数として、"~"の後に集計したい(カテゴリ)変数名を指定します。すると、その変数を区分する要因(水準)ごとの集計がされます。2つ以上の変数の分割表を作るには、変数名を"+"でつなぎます。最後に指定した変数が、列変数となります。作成される表データは、行列matrixという種類のオブジェクトです。オブジェクトの種類を調べるにはclass( )関数を使います。
Rで使う変数などのオブジェクトには、数値、文字列、論理値、関数、行列(matrix)、リストなどのタイプがあります。型を調べるにはclass( )にオブジェクトを渡します。as.xxx( )関数を使うと、現在の型を別のxxx型に変換することができます。
ここでは、上で作成した頻度分割表(yoji.tab)のうち、女性の頻度データ(1行目)と男性の頻度データ(2行目)を、一度数値ベクトルに変換します。変換した数値ベクトルに基づいて、散らばり指数を計算するためです。
カテゴリデータの各水準の頻度に基づいて散らばり指数を計算します。データ総数をN, 水準数をc、i 番目の水準の頻度を xiとすると、 散らばり指数 D の計算式は次の通りです。(山内 光哉 1998『心理・教育のための統計法』より)
散らばり指数の計算のように、繰り返し使う可能性のある、一連の演算作業は関数の形で作成しておくと便利です。Rでは自分で関数を定義しておき、必要なときに呼び出して使うことができます。関数を定義するときはfunction( )関数を使い、必要があれば引数を指定します。関数名を数字で始めることはできません。"{ }"で囲まれたブロックの中に処理内容を書き、return( )関数を使って計算結果などを返すことができます。
散らばり指数を計算する関数 dispersion( ) を定義してみましょう。
この関数に、3.3.1で格納した、女性や男性の4字熟語使用頻度ベクトルを渡すと次のようになります。男性データの散らばり指数の方が大きな値を返します。
Rを終了する際に、「作業スペースを保存」して終了すると、関数オブジェクトも(他のオブジェクトと同様に)保存されます。次回Rを起動したときに、関数を呼び出して使うことができます。
関数の定義をテキストファイルに書いて、たとえばdispersion.Rという名前で保存します。これをRスクリプトといい、Rコンソール画面で、「ファイル」メニューの「Rコードのソース読み込み」から呼び出すこともできます。source( )関数を使うこともできます。