

| 丂丂[4.1] 嫟暘嶶偲憡娭學悢 |
| 丂丂[4.2] 嶶晍恾 |
| 丂丂[4.3] 憡娭峴楍丄嶶晍恾峴楍 |
| 丂丂[4.4] 憡娭學悢偲斖埻偺岠壥 |
俀偮偺楢懕曄検偺娭學傪昞偡広搙偲偟偰丄僺傾僜儞偺愊棪憡娭學悢(correlative coefficient)偑偁傝傑偡丅憡娭學悢倰偼丄嫟暘嶶傪丄倃偲倄偺昗弨曃嵎偺愊偱妱偭偨抣偱偡丅嫟暘嶶(covariance)偼丄倃偺曃嵎偲倄偺曃嵎偺愊偺憤榓偱偡丅
嫟暘嶶偲憡娭學悢偺抣傪岞幃捠傝偵嶼弌偡傞偙偲傕偱偒傑偡偑丄傛偔巊偆偺偱丄娭悢偑梡堄偝傟偰偄傑偡丅
俀曄検倃丄倄偺抣傪倃幉丄倄幉偵僾儘僢僩偟偨僌儔僼傪嶶晍恾(scatter plot)偲尵偄傑偡丅俼偱嶶晍恾傪昤偔偵偼丄俀曄検傪巜掕偡傞偩偗偱偡丅曄検侾偑倃幉丄曄検俀偑倄幉偲側傝傑偡丅
plot( ) 偵偼丄栚揑偵墳偠偰丄僨乕僞揰偺宍丄怓側偳丄偝傑偞傑側僆僾僔儑儞巜掕偑壜擻偲側偭偰偄傑偡丅
| 庡側怓巜掕 | 昞帵怓 | 庡側宍巜掕 | 昞帵宍 |
|---|---|---|---|
| col=1, col="black" | 崟 | pch=1 | 仜 |
| col=2, col="red" | 愒 | pch=2 | 仮 |
| col=3, col="green" | 椢 | pch=3 | 亄 |
| col=4, col="blue" | 惵 | pch=4 | 亊 |
| col=5, col="aqua" | 悈怓 | pch=5 | 仦 |
| col=6, col="pink" | 搷怓 | pch=6 | 仱 |
| col=7, col="yellow" | 墿怓 | pch=16 | 仠 |
| col=8, col="grey" | 奃怓 | pch=17 | 仯 |
|
|
捠忢偼丄僌儔僼夋柺偵侾偮偺僌儔僼偑昤夋偝傟傞傛偆偵側偭偰偄傑偡丅帪偲偟偰丄暋悢偺僌儔僼傪暲傋偰昤夋偟偨偄偲偒偑偁傝傑偡丅偦偺傛偆側偲偒偼丄昤夋偡傞嵺偺愝掕儌乕僪(parameter)偺僆僾僔儑儞巜掕傪峴偄傑偡丅暋悢昤夋偺応崌偵偼丄mfrow( )傪巊偄傑偡丅巊梡屻偼丄僨僼僅儖僩偺愝掕偵栠偟偰偍偒傑偡丅
嶶晍恾偺忋偵丄夞婣捈慄傪捛壛偡傞偙偲偑偱偒傑偡丅捈慄傪堷偔偵偼lines( )娭悢傪梡偄傑偡偑丄俀偮偺揰偺倃嵗昗偲倄嵗昗偺抣傪巜掕偡傞昁梫偑偁傝傑偡丅倷愗曅倎偍傛傃孹偒倐偺抣偑傢偐偭偰偄傞偲偒偵偼丄abline( )娭悢傪巊偄傑偡丅
丂捈慄偵娭偟偰傕丄慄偺庬椶丄怓傗懢偝側偳傪僆僾僔儑儞巜掕偡傞偙偲偑偱偒傑偡丅
夞婣捈慄偺抣傪媮傔傞偵偼丄慄宍儌僨儖lm( )傪巊偭偰夞婣暘愅傪峴偆昁梫偑偁傝傑偡丅夞婣暘愅偺寢壥偺梫栺偼summary( )偱帵偝傟傑偡丅偙偺寢壥傪尒偰丄abline( )娭悢偵愗曅(intecept)偲孹偒偺悇掕抣(estimate)傪擖椡偡傞偐丄偁傞偄偼丄夞婣暘愅偺寢壥傪堷悢偲偟偰搉偡偙偲傕偱偒傑偡丅


|
嵟屻偵丄僌儔僼拞偵僥僉僗僩傪捛壛偡傞偵偼丄text( )傪巊偭偰丄捛壛偡傞僥僉僗僩偲捛壛偡傞応強傪巜掕偟傑偡丅応強傪嵗昗(x,y)偱巜掕偡傞偙偲傕偱偒傑偡偑丄locator(1)偲偡傞偲儅僂僗偵傛偭偰応強巜掕偡傞偙偲傕偱偒傑偡丅巜掕嵗昗傗儅僂僗偺亄偺埵抲偑丄揬傝晅偗傜傟傞僥僉僗僩偺拞怱偲側傝傑偡丅
丂僥僉僗僩傪僌儔僼偺廃曈偵捛壛偡傞偵偼丄mtext( ) 傪巊偄傑偡丅乮倣偼margin偺堄枴偱偡乯係偮偺廃曈偑偁傝傑偡偺偱丄悢抣偱応強傪巜掕偟傑偡丅side=3偲偡傞偲僌儔僼偺忋曈偵昞帵偝傟傑偡偑丄偙傟偼庡僞僀僩儖乮僌儔僼僉儍僾僔儑儞乯傛傝傕壓偺埵抲偱偡丅
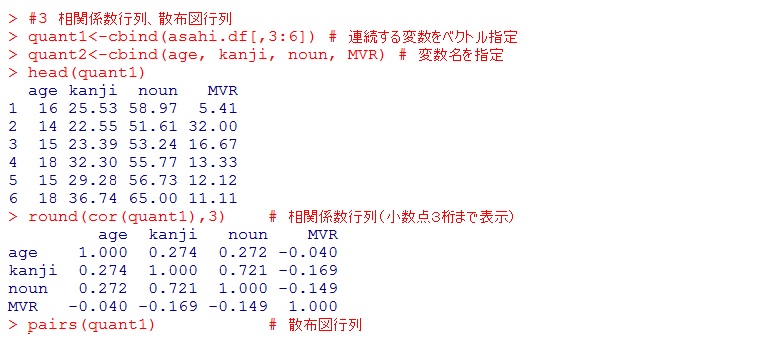
暋悢偺曄検偺娫偺丄俀曄検偺憡娭學悢傗嶶晍恾傪憤摉偨傝偱媮傔傞偙偲偑偱偒傑偡丅cor( )偁傞偄偼pairs( )娭悢偵丄懳徾偲側傞曄悢傪儀僋僩儖偵偟偰搉偟傑偡丅
懳徾偲側傞曄悢偺楍偑楢懕偟偰偄傞偲偒偼 ":" 偱巜掕偱偒傑偡丅楍(column)偑楢懕偟偰偄側偄曄悢傪懇偹傞偵偼丄cbind( )娭悢傪巊偭偰丄堦搙怴偨側僨乕僞僙僢僩傪嶌偭偰偐傜丄嶌嬈偟傑偡丅
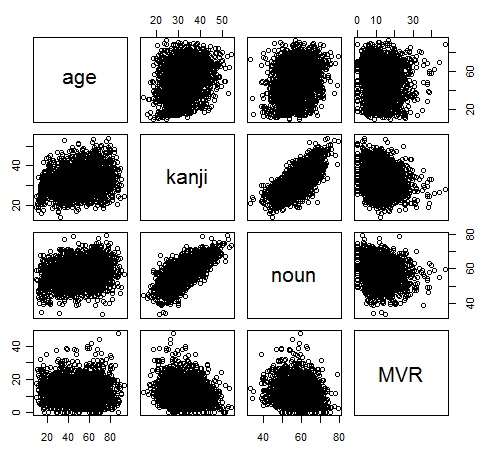
搳彂僨乕僞偺拞偺悢検僨乕僞乮擭楊傪娷傔傞乯偩偗偐傜側傞怴偨側僨乕僞僙僢僩傪嶌傝丄憡娭峴楍偲嶶晍恾峴楍傪嶌偭偰傒傑偟傚偆丅
|
|
偁傞俀曄検偺丄慡懱偺憡娭學悢偲丄慡懱偺偆偪偺堦晹偩偗偺憡娭學悢傪斾妑偡傞偲丄堦晹偩偗偺僨乕僞偺憡娭學悢偺傎偆偑彫偝偔側傞偲尵傢傟偰偄傑偡丅
慡懱僨乕僞偺拞偐傜丄忦審傪枮偨偡堦晹偺僨乕僞傪拪弌偡傞偵偼丄壓埵廤崌傪庢傞subset( )娭悢傪梡偄傑偡丅崱丄懳徾曄悢傪df, 拪弌忦審傪巜掕偡傞曄悢傪x偲偟傑偡丅
偙偙偱偼丄乽壽戣乿偵増偭偰丄娍帤棪偲柤帉棪僨乕僞偺堦晹傪拪弌偟偰丄慡懱偺憡娭學悢偲斾妑偟偰傒傑偡丅拪弌忦審傪擭楊偑30嵨埲忋50嵨枹枮偲愝掕偟傑偡丅

|
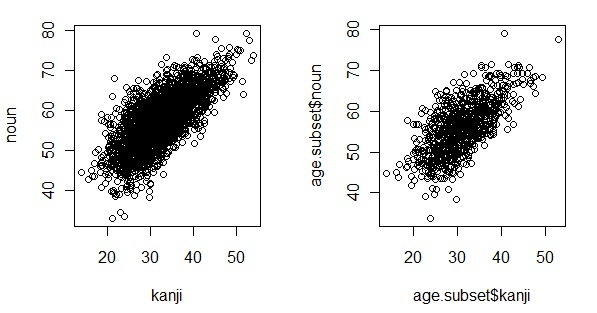
慡懱僨乕僞偺嶶晍恾偲丄堦晹僨乕僞偺嶶晍恾傪斾妑偡傞偨傔偵丄僌儔僼傿僢僋夋柺偵俀偮偺僌儔僼傪暲傋偰昤夋偟偰傒傑偟傚偆丅

|
|
嵍偑慡懱僨乕僞偺嶶晍恾偱丄塃偑堦晹僨乕僞偺嶶晍恾偱偡丅嶶晍恾偱憡娭傪斾妑偡傞偲堘偄偑傛偔傢偐傝傑偣傫丅憡娭學悢偱斾妑偡傞偲丄慡懱偱0.72, 堦晹僨乕僞偺傎偆偑0.68偱偡偺偱丄悢抣揑偵偼彫偝偔側偭偰偄傑偡丅